

はじめに
以下のチュートリアルを試す
https://aws.amazon.com/jp/tutorials/machine-learning-tutorial-mlops-automate-ml-workflows
このチュートリアルでは、Amazon SageMaker Pipelines、SageMaker Model Registry、SageMaker Clarifyを使用して、エンドツーエンドの機械学習(ML)ワークフローを自動化する方法を学びます。
- SageMaker Pipelinesは、ML用のCI/CDサービスで、データの読み込み、変換、トレーニング、チューニング、評価、デプロイなどのステップを自動化できます。
- SageMaker Model Registryは、モデルのバージョンやメタデータ、パフォーマンスを管理し、ビジネス要件に応じた最適なモデルの選択をサポートします。
- SageMaker Clarifyは、データやモデルのバイアスを検出し、予測の説明可能性を提供します。
このチュートリアルでは、XGBoostを使用して自動車保険の詐欺申請を予測するバイナリ分類モデルを構築、トレーニング、デプロイします。合成データセットを使い、保険データの生データを処理し、トレーニング、検証、テストデータセットを作成します。最後に、SageMaker Clarifyでモデルのバイアスをテストし、説明可能性を確認した後、モデルをデプロイします。
チュートリアルの実行
SageMaker Studioドメインの生成
参照:https://www.s3lab.co.jp/blog/iaas/amazon/2253/
SageMaker Studio notebook の生成とPipelineの変数設定
このステップでは、新しいSageMaker Studio notebookを起動し、s3とやり取りするために必要なSageMakerの変数を設定します。
notebookを生成する
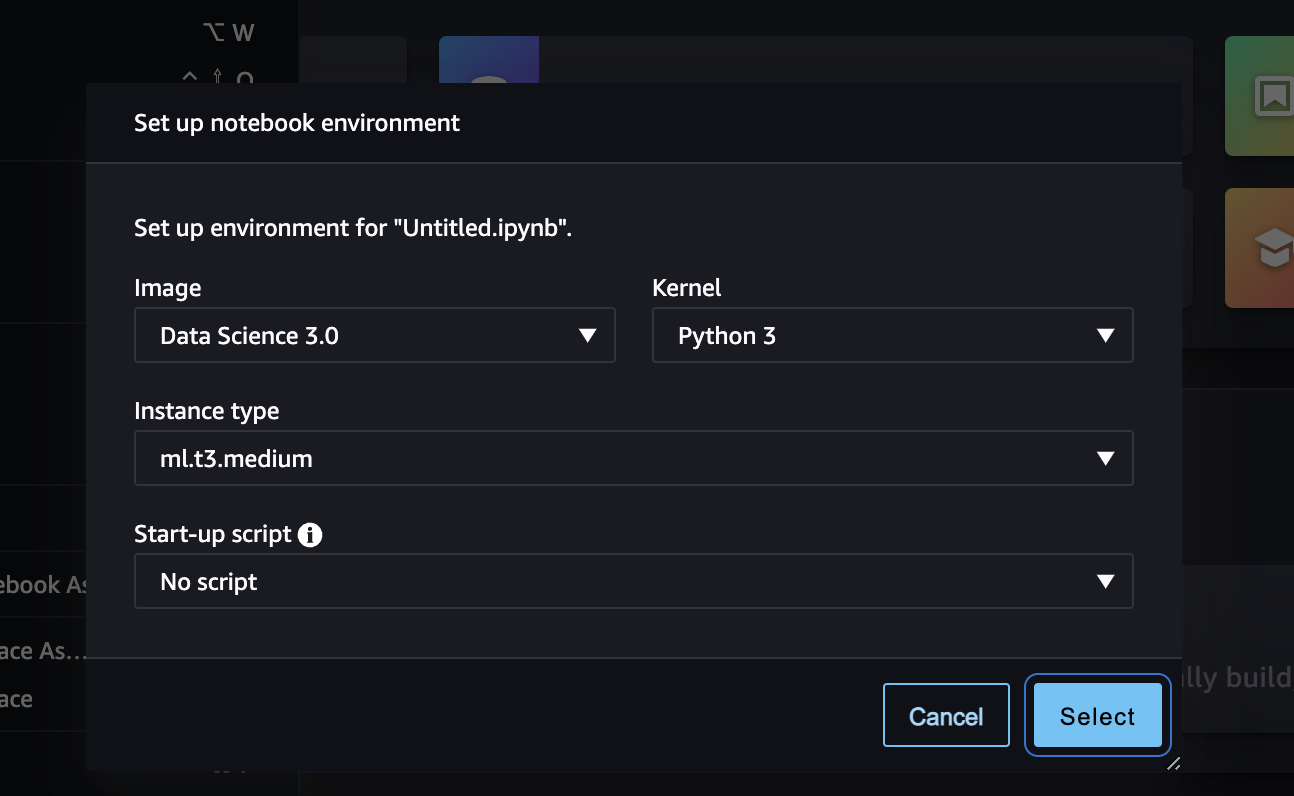
ライブラリを準備する
import pandas as pd
import json
import boto3
import pathlib
import io
import sagemaker
from sagemaker.deserializers import CSVDeserializer
from sagemaker.serializers import CSVSerializer
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor
)
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import (
ProcessingStep,
TrainingStep,
CreateModelStep
)
from sagemaker.workflow.check_job_config import CheckJobConfig
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterFloat,
ParameterString,
ParameterBoolean
)
from sagemaker.workflow.clarify_check_step import (
ModelBiasCheckConfig,
ClarifyCheckStep,
ModelExplainabilityCheckConfig
)
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
from sagemaker.lambda_helper import Lambda
from sagemaker.model_metrics import (
MetricsSource,
ModelMetrics,
FileSource
)
from sagemaker.drift_check_baselines import DriftCheckBaselines
from sagemaker.image_uris import retrieveSageMakerとS3のboto3クライアントの準備
以下のコードで、SageMakerとS3クライアントオブジェクトを設定します。これにより、SageMakerがエンドポイントのデプロイや呼び出し、Amazon S3やAWS Lambdaとの連携を行うことができるようになります。コードでは、データセットやモデルのアーティファクトを保存するS3バケットの場所も設定します。読み込み用バケット(sagemaker-sample-files)は公開S3バケットで生データが含まれ、書き込み用バケットはアカウントに紐付いたデフォルトのS3バケットで、処理済みデータやアーティファクトが保存されます。
# Instantiate AWS services session and client objects
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
# Fetch SageMaker execution role
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
# S3 location where raw data to be fetched from
raw_data_key = f"s3://{read_bucket}/{read_prefix}"
# S3 location where processed data to be uploaded
processed_data_key = f"{write_prefix}/processed"
# S3 location where train data to be uploaded
train_data_key = f"{write_prefix}/train"
# S3 location where validation data to be uploaded
validation_data_key = f"{write_prefix}/validation"
# S3 location where test data to be uploaded
test_data_key = f"{write_prefix}/test"
# Full S3 paths
claims_data_uri = f"{raw_data_key}/claims.csv"
customers_data_uri = f"{raw_data_key}/customers.csv"
output_data_uri = f"s3://{write_bucket}/{write_prefix}/"
scripts_uri = f"s3://{write_bucket}/{write_prefix}/scripts"
estimator_output_uri = f"s3://{write_bucket}/{write_prefix}/training_jobs"
processing_output_uri = f"s3://{write_bucket}/{write_prefix}/processing_jobs"
model_eval_output_uri = f"s3://{write_bucket}/{write_prefix}/model_eval"
clarify_bias_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/bias_config"
clarify_explainability_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/explainability_config"
bias_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/bias"
explainability_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/explainability"
# Retrieve training image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")SageMakerパイプラインの各コンポーネントの名前の設定
以下のコードで、モデルやエンドポイントなど、SageMakerパイプラインの各コンポーネントの名前を設定します。また、トレーニングと推論に使用するインスタンスタイプやインスタンス数も指定します。これらの値は、パイプラインをパラメータ化する際に使用されます。
# Set names of pipeline objects
pipeline_name = "FraudDetectXGBPipeline"
pipeline_model_name = "fraud-detect-xgb-pipeline"
model_package_group_name = "fraud-detect-xgb-model-group"
base_job_name_prefix = "fraud-detect"
endpoint_config_name = f"{pipeline_model_name}-endpoint-config"
endpoint_name = f"{pipeline_model_name}-endpoint"
# Set data parameters
target_col = "fraud"
# Set instance types and counts
process_instance_type = "ml.c5.xlarge"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.m4.xlarge"
clarify_instance_count = 1
clarify_instance_type = "ml.m4.xlarge"Pipeline入力パラメータ設定
SageMaker Pipelinesはパラメータ化をサポートしており、パイプラインコードを変更せずに実行時に入力パラメータを指定できます。sagemaker.workflow.parametersモジュール内のParameterInteger、ParameterFloat、ParameterString、ParameterBooleanを使って、様々なデータ型のパイプラインパラメータを設定できます。以下のコードで、SageMaker Clarify設定を含む複数の入力パラメータを設定します。
# Set up pipeline input parameters
# Set processing instance type
process_instance_type_param = ParameterString(
name="ProcessingInstanceType",
default_value=process_instance_type,
)
# Set training instance type
train_instance_type_param = ParameterString(
name="TrainingInstanceType",
default_value=train_instance_type,
)
# Set training instance count
train_instance_count_param = ParameterInteger(
name="TrainingInstanceCount",
default_value=train_instance_count
)
# Set deployment instance type
deploy_instance_type_param = ParameterString(
name="DeployInstanceType",
default_value=predictor_instance_type,
)
# Set deployment instance count
deploy_instance_count_param = ParameterInteger(
name="DeployInstanceCount",
default_value=predictor_instance_count
)
# Set Clarify check instance type
clarify_instance_type_param = ParameterString(
name="ClarifyInstanceType",
default_value=clarify_instance_type,
)
# Set model bias check params
skip_check_model_bias_param = ParameterBoolean(
name="SkipModelBiasCheck",
default_value=False
)
register_new_baseline_model_bias_param = ParameterBoolean(
name="RegisterNewModelBiasBaseline",
default_value=False
)
supplied_baseline_constraints_model_bias_param = ParameterString(
name="ModelBiasSuppliedBaselineConstraints",
default_value=""
)
# Set model explainability check params
skip_check_model_explainability_param = ParameterBoolean(
name="SkipModelExplainabilityCheck",
default_value=False
)
register_new_baseline_model_explainability_param = ParameterBoolean(
name="RegisterNewModelExplainabilityBaseline",
default_value=False
)
supplied_baseline_constraints_model_explainability_param = ParameterString(
name="ModelExplainabilitySuppliedBaselineConstraints",
default_value=""
)
# Set model approval param
model_approval_status_param = ParameterString(
name="ModelApprovalStatus", default_value="Approved"
)Pipelineコンポーネントの構築
パイプラインは、一連のステップを個別に構築し、それらを組み合わせて機械学習ワークフローを形成するものです。以下の図は、パイプラインの主要なステップを示しています。
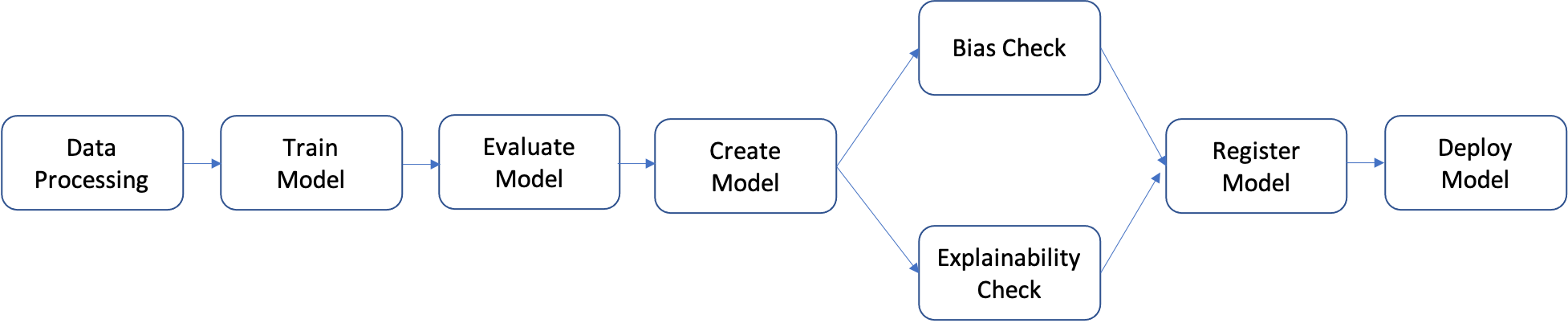
このチュートリアルでは、以下のステップでパイプラインを構築します:
- データ処理ステップ: S3の生データを使い、トレーニング、検証、テストデータに分割してS3に保存。
- トレーニングステップ: XGBoostモデルをS3のトレーニングと検証データで訓練し、モデルをS3に保存。
- 評価ステップ: テストデータとモデルを使い、S3にモデル評価レポートを保存。
- 条件付きステップ: モデルのパフォーマンスが基準を満たすかチェックし、条件を満たした場合のステップを実行。
- モデル作成ステップ: モデルをS3に保存。
- バイアスチェックステップ: SageMaker Clarifyでモデルバイアスをチェックし、レポートをS3に保存。
- モデル説明可能性ステップ: SageMaker Clarifyでモデルの説明可能性を評価し、レポートをS3に保存。
- 登録ステップ: モデル、バイアス、説明可能性のメトリクスを使い、モデルをSageMaker Model Registryに登録。
- デプロイステップ: AWS Lambdaハンドラーを使い、モデルをリアルタイム推論エンドポイントにデプロイ。
SageMaker Pipelinesには、データ処理、モデル訓練などのプリセットされたステップが提供されており、これらのステップを組み合わせてパイプラインを構築します。
以下のコードで、preprocessing.pyを作成します。
%%writefile preprocessing.py
import argparse
import pathlib
import boto3
import os
import pandas as pd
import logging
from sklearn.model_selection import train_test_split
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-ratio", type=float, default=0.8)
parser.add_argument("--validation-ratio", type=float, default=0.1)
parser.add_argument("--test-ratio", type=float, default=0.1)
args, _ = parser.parse_known_args()
logger.info("Received arguments {}".format(args))
# Set local path prefix in the processing container
local_dir = "/opt/ml/processing"
input_data_path_claims = os.path.join("/opt/ml/processing/claims", "claims.csv")
input_data_path_customers = os.path.join("/opt/ml/processing/customers", "customers.csv")
logger.info("Reading claims data from {}".format(input_data_path_claims))
df_claims = pd.read_csv(input_data_path_claims)
logger.info("Reading customers data from {}".format(input_data_path_customers))
df_customers = pd.read_csv(input_data_path_customers)
logger.debug("Formatting column names.")
# Format column names
df_claims = df_claims.rename({c : c.lower().strip().replace(' ', '_') for c in df_claims.columns}, axis = 1)
df_customers = df_customers.rename({c : c.lower().strip().replace(' ', '_') for c in df_customers.columns}, axis = 1)
logger.debug("Joining datasets.")
# Join datasets
df_data = df_claims.merge(df_customers, on = 'policy_id', how = 'left')
# Drop selected columns not required for model building
df_data = df_data.drop(['customer_zip'], axis = 1)
# Select Ordinal columns
ordinal_cols = ["police_report_available", "policy_liability", "customer_education"]
# Select categorical columns and filling with na
cat_cols_all = list(df_data.select_dtypes('object').columns)
cat_cols = [c for c in cat_cols_all if c not in ordinal_cols]
df_data[cat_cols] = df_data[cat_cols].fillna('na')
logger.debug("One-hot encoding categorical columns.")
# One-hot encoding categorical columns
df_data = pd.get_dummies(df_data, columns = cat_cols)
logger.debug("Encoding ordinal columns.")
# Ordinal encoding
mapping = {
"Yes": "1",
"No": "0"
}
df_data['police_report_available'] = df_data['police_report_available'].map(mapping)
df_data['police_report_available'] = df_data['police_report_available'].astype(float)
mapping = {
"15/30": "0",
"25/50": "1",
"30/60": "2",
"100/200": "3"
}
df_data['policy_liability'] = df_data['policy_liability'].map(mapping)
df_data['policy_liability'] = df_data['policy_liability'].astype(float)
mapping = {
"Below High School": "0",
"High School": "1",
"Associate": "2",
"Bachelor": "3",
"Advanced Degree": "4"
}
df_data['customer_education'] = df_data['customer_education'].map(mapping)
df_data['customer_education'] = df_data['customer_education'].astype(float)
df_processed = df_data.copy()
df_processed.columns = [c.lower() for c in df_data.columns]
df_processed = df_processed.drop(["policy_id", "customer_gender_unkown"], axis=1)
# Split into train, validation, and test sets
train_ratio = args.train_ratio
val_ratio = args.validation_ratio
test_ratio = args.test_ratio
logger.debug("Splitting data into train, validation, and test sets")
y = df_processed['fraud']
X = df_processed.drop(['fraud'], axis = 1)
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=test_ratio, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=val_ratio, random_state=42)
train_df = pd.concat([y_train, X_train], axis = 1)
val_df = pd.concat([y_val, X_val], axis = 1)
test_df = pd.concat([y_test, X_test], axis = 1)
dataset_df = pd.concat([y, X], axis = 1)
logger.info("Train data shape after preprocessing: {}".format(train_df.shape))
logger.info("Validation data shape after preprocessing: {}".format(val_df.shape))
logger.info("Test data shape after preprocessing: {}".format(test_df.shape))
# Save processed datasets to the local paths in the processing container.
# SageMaker will upload the contents of these paths to S3 bucket
logger.debug("Writing processed datasets to container local path.")
train_output_path = os.path.join(f"{local_dir}/train", "train.csv")
validation_output_path = os.path.join(f"{local_dir}/val", "validation.csv")
test_output_path = os.path.join(f"{local_dir}/test", "test.csv")
full_processed_output_path = os.path.join(f"{local_dir}/full", "dataset.csv")
logger.info("Saving train data to {}".format(train_output_path))
train_df.to_csv(train_output_path, index=False)
logger.info("Saving validation data to {}".format(validation_output_path))
val_df.to_csv(validation_output_path, index=False)
logger.info("Saving test data to {}".format(test_output_path))
test_df.to_csv(test_output_path, index=False)
logger.info("Saving full processed data to {}".format(full_processed_output_path))
dataset_df.to_csv(full_processed_output_path, index=False)
SKLearnProcessorによるジョブ定義とProcessingStepによるPipelineステップ定義
以下のコードで、プロセッサとSageMaker Pipelinesの処理ステップを作成します。Pandasで書かれた処理スクリプトを実行するために、SKLearnProcessorを使用します。SageMaker Pipelines ProcessingStep関数には、プロセッサ、生データセットのS3入力場所、処理済みデータセットのS3出力場所を指定します。さらに、トレーニング、検証、テストデータの分割比率などの追加引数はjob_argumentsを通じて渡されます。
from sagemaker.workflow.pipeline_context import PipelineSession
# Upload processing script to S3
s3_client.upload_file(
Filename="preprocessing.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/preprocessing.py"
)
# Define the SKLearnProcessor configuration
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
role=sagemaker_role,
instance_count=1,
instance_type=process_instance_type,
base_job_name=f"{base_job_name_prefix}-processing",
)
# Define pipeline processing step
process_step = ProcessingStep(
name="DataProcessing",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=claims_data_uri, destination="/opt/ml/processing/claims"),
ProcessingInput(source=customers_data_uri, destination="/opt/ml/processing/customers")
],
outputs=[
ProcessingOutput(destination=f"{processing_output_uri}/train_data", output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(destination=f"{processing_output_uri}/validation_data", output_name="validation_data", source="/opt/ml/processing/val"),
ProcessingOutput(destination=f"{processing_output_uri}/test_data", output_name="test_data", source="/opt/ml/processing/test"),
ProcessingOutput(destination=f"{processing_output_uri}/processed_data", output_name="processed_data", source="/opt/ml/processing/full")
],
job_arguments=[
"--train-ratio", "0.8",
"--validation-ratio", "0.1",
"--test-ratio", "0.1"
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/preprocessing.py"
)トレーニングスクリプトの準備
以下のコードで、XGBoostバイナリ分類器のトレーニングロジックを含むトレーニングスクリプトを準備します。モデルのトレーニングで使用されるハイパーパラメータは、後のチュートリアルでトレーニングステップの定義を通じて提供されます。
xgboost_train.pyファイルを生成する
%%writefile xgboost_train.py
import argparse
import os
import joblib
import json
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Hyperparameters and algorithm parameters are described here
parser.add_argument("--num_round", type=int, default=100)
parser.add_argument("--max_depth", type=int, default=3)
parser.add_argument("--eta", type=float, default=0.2)
parser.add_argument("--subsample", type=float, default=0.9)
parser.add_argument("--colsample_bytree", type=float, default=0.8)
parser.add_argument("--objective", type=str, default="binary:logistic")
parser.add_argument("--eval_metric", type=str, default="auc")
parser.add_argument("--nfold", type=int, default=3)
parser.add_argument("--early_stopping_rounds", type=int, default=3)
# SageMaker specific arguments. Defaults are set in the environment variables
# Set location of input training data
parser.add_argument("--train_data_dir", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
# Set location of input validation data
parser.add_argument("--validation_data_dir", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
# Set location where trained model will be stored. Default set by SageMaker, /opt/ml/model
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
# Set location where model artifacts will be stored. Default set by SageMaker, /opt/ml/output/data
parser.add_argument("--output_data_dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR"))
args = parser.parse_args()
data_train = pd.read_csv(f"{args.train_data_dir}/train.csv")
train = data_train.drop("fraud", axis=1)
label_train = pd.DataFrame(data_train["fraud"])
dtrain = xgb.DMatrix(train, label=label_train)
data_validation = pd.read_csv(f"{args.validation_data_dir}/validation.csv")
validation = data_validation.drop("fraud", axis=1)
label_validation = pd.DataFrame(data_validation["fraud"])
dvalidation = xgb.DMatrix(validation, label=label_validation)
# Choose XGBoost model hyperparameters
params = {"max_depth": args.max_depth,
"eta": args.eta,
"objective": args.objective,
"subsample" : args.subsample,
"colsample_bytree":args.colsample_bytree
}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
# Cross-validate train XGBoost model
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=nfold,
early_stopping_rounds=early_stopping_rounds,
metrics=["auc"],
seed=42,
)
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
train_pred = model.predict(dtrain)
validation_pred = model.predict(dvalidation)
train_auc = roc_auc_score(label_train, train_pred)
validation_auc = roc_auc_score(label_validation, validation_pred)
print(f"[0]#011train-auc:{train_auc:.2f}")
print(f"[0]#011validation-auc:{validation_auc:.2f}")
metrics_data = {"hyperparameters" : params,
"binary_classification_metrics": {"validation:auc": {"value": validation_auc},
"train:auc": {"value": train_auc}
}
}
# Save the evaluation metrics to the location specified by output_data_dir
metrics_location = args.output_data_dir + "/metrics.json"
# Save the trained model to the location specified by model_dir
model_location = args.model_dir + "/xgboost-model"
with open(metrics_location, "w") as f:
json.dump(metrics_data, f)
with open(model_location, "wb") as f:
joblib.dump(model, f)TrainingStepによるトレーニングステップの定義
SageMaker XGBoost推定器とSageMaker PipelinesのTrainingStep関数を使用して、モデルのトレーニングを設定します。
# Set XGBoost model hyperparameters
hyperparams = {
"eval_metric" : "auc",
"objective": "binary:logistic",
"num_round": "5",
"max_depth":"5",
"subsample":"0.75",
"colsample_bytree":"0.75",
"eta":"0.5"
}
# Set XGBoost estimator
xgb_estimator = XGBoost(
entry_point="xgboost_train.py",
output_path=estimator_output_uri,
code_location=estimator_output_uri,
hyperparameters=hyperparams,
role=sagemaker_role,
# Fetch instance type and count from pipeline parameters
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.3-1"
)
# Access the location where the preceding processing step saved train and validation datasets
# Pipeline step properties can give access to outputs which can be used in succeeding steps
s3_input_train = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
s3_input_validation = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["validation_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
# Set pipeline training step
train_step = TrainingStep(
name="XGBModelTraining",
estimator=xgb_estimator,
inputs={
"train":s3_input_train, # Train channel
"validation": s3_input_validation # Validation channel
}
)SageMakerモデルの生成
以下のコードで、SageMaker PipelinesのCreateModelStep関数を使ってSageMakerモデルを作成します。このステップでは、トレーニングステップの出力を利用して、モデルをデプロイ用にパッケージ化します。インスタンスタイプの値は、チュートリアルの前半で定義したSageMaker Pipelinesのパラメータを使用します。
# Create a SageMaker model
model = sagemaker.model.Model(
image_uri=training_image,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sess,
role=sagemaker_role
)
# Specify model deployment instance type
inputs = sagemaker.inputs.CreateModelInput(instance_type=deploy_instance_type_param)
create_model_step = CreateModelStep(name="FraudDetModel", model=model, inputs=inputs)ClarifyCheckStepによるPipelineバイアス評価ステップの定義
機械学習ワークフローでは、トレーニング済みモデルのバイアスを評価し、入力データの各特徴が予測にどのように影響するかを理解することが重要です。SageMaker PipelinesのClarifyCheckStep関数を使うと、データバイアス(トレーニング前)、モデルバイアス(トレーニング後)、モデル説明可能性の3種類のチェックを実行できます。このチュートリアルでは、実行時間を短縮するために、バイアスと説明可能性のチェックのみを行います。以下のコードをコピーして実行し、モデルバイアスチェックの設定を行います。このステップでは、前のステップで作成されたトレーニングデータやSageMakerモデルを使用します。また、コスト管理と実行時間短縮のために、バイアスメトリクスは「DPPL」のみを計算します。
# Set up common configuration parameters to be used across multiple steps
check_job_config = CheckJobConfig(
role=sagemaker_role,
instance_count=1,
instance_type=clarify_instance_type,
volume_size_in_gb=30,
sagemaker_session=sess,
)
# Set up configuration of data to be used for model bias check
model_bias_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=bias_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_bias_config_output_uri
)
# Set up details of the trained model to be checked for bias
model_config = sagemaker.clarify.ModelConfig(
# Pull model name from model creation step
model_name=create_model_step.properties.ModelName,
instance_count=train_instance_count,
instance_type=train_instance_type
)
# Set up column and categories that are to be checked for bias
model_bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1]
)
# Set up model predictions configuration to get binary labels from probabilities
model_predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
model_bias_check_config = ModelBiasCheckConfig(
data_config=model_bias_data_config,
data_bias_config=model_bias_config,
model_config=model_config,
model_predicted_label_config=model_predictions_config,
methods=["DPPL"]
)
# Set up pipeline model bias check step
model_bias_check_step = ClarifyCheckStep(
name="ModelBiasCheck",
clarify_check_config=model_bias_check_config,
check_job_config=check_job_config,
skip_check=skip_check_model_bias_param,
register_new_baseline=register_new_baseline_model_bias_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_bias_param
)ClarifyCheckStepによるPipelineモデルの説明可能性チェックステップの定義
以下のコードにより、モデルの説明可能性チェックを設定します。このステップでは、特徴量の重要度(入力特徴がモデルの予測にどのように影響するか)などのインサイトを提供します。
# Set configuration of data to be used for model explainability check
model_explainability_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=explainability_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_explainability_config_output_uri
)
# Set SHAP configuration for Clarify to compute global and local SHAP values for feature importance
shap_config = sagemaker.clarify.SHAPConfig(
seed=42,
num_samples=100,
agg_method="mean_abs",
save_local_shap_values=True
)
model_explainability_config = ModelExplainabilityCheckConfig(
data_config=model_explainability_data_config,
model_config=model_config,
explainability_config=shap_config
)
# Set pipeline model explainability check step
model_explainability_step = ClarifyCheckStep(
name="ModelExplainabilityCheck",
clarify_check_config=model_explainability_config,
check_job_config=check_job_config,
skip_check=skip_check_model_explainability_param,
register_new_baseline=register_new_baseline_model_explainability_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_explainability_param
)ROC-AUCスコアによる評価スクリプトの準備
本番環境では、すべてのトレーニング済みモデルがデプロイされるわけではなく、通常は評価指標が基準を超えたモデルのみがデプロイされます。このステップでは、ROC-AUC(受信者操作特性曲線の下の面積)を用いてモデルのスコアをテストセットで評価するPythonスクリプトを作成します。この評価結果を基に、モデルを登録・デプロイするかどうかを判断します。テストデータを使用してAUCメトリクスを生成する評価スクリプトを作成するためのコードをコピーして実行します。
https://qiita.com/osapiii/items/a2ed9f638b51f3b22cd6
https://www.kikagaku.co.jp/kikagaku-blog/roc-auc
以下のコードで、evaluate.pyを生成する
%%writefile evaluate.py
import json
import logging
import pathlib
import pickle
import tarfile
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
model_path = "/opt/ml/processing/model/model.tar.gz"
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
logger.debug("Loading xgboost model.")
# The name of the file should match how the model was saved in the training script
model = pickle.load(open("xgboost-model", "rb"))
logger.debug("Reading test data.")
test_local_path = "/opt/ml/processing/test/test.csv"
df_test = pd.read_csv(test_local_path)
# Extract test set target column
y_test = df_test.iloc[:, 0].values
cols_when_train = model.feature_names
# Extract test set feature columns
X = df_test[cols_when_train].copy()
X_test = xgb.DMatrix(X)
logger.info("Generating predictions for test data.")
pred = model.predict(X_test)
# Calculate model evaluation score
logger.debug("Calculating ROC-AUC score.")
auc = roc_auc_score(y_test, pred)
metric_dict = {
"classification_metrics": {"roc_auc": {"value": auc}}
}
# Save model evaluation metrics
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
logger.info("Writing evaluation report with ROC-AUC: %f", auc)
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(metric_dict))ScriptProcessorによるモデル評価スタップの定義
次に、以下のコードにより、評価スクリプトを実行するためのプロセッサとSageMaker Pipelinesのステップを作成します。カスタムスクリプトを処理するためにScriptProcessorを使用します。ProcessingStep関数には、プロセッサ、テストデータセットとモデルアーティファクトのS3入力場所、評価結果を保存する出力場所が引数として渡されます。さらに、property_files引数を使って、評価結果(モデルのパフォーマンス指標が含まれるjsonファイル)を保存します。この情報は、後のチュートリアルで条件付きステップを実行するかどうかを判断する際に役立ちます。
# Upload model evaluation script to S3
s3_client.upload_file(
Filename="evaluate.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/evaluate.py"
)
eval_processor = ScriptProcessor(
image_uri=training_image,
command=["python3"],
instance_type=predictor_instance_type,
instance_count=predictor_instance_count,
base_job_name=f"{base_job_name_prefix}-model-eval",
sagemaker_session=sess,
role=sagemaker_role,
)
evaluation_report = PropertyFile(
name="FraudDetEvaluationReport",
output_name="evaluation",
path="evaluation.json",
)
# Set model evaluation step
evaluation_step = ProcessingStep(
name="XGBModelEvaluate",
processor=eval_processor,
inputs=[
ProcessingInput(
# Fetch S3 location where train step saved model artifacts
source=train_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
# Fetch S3 location where processing step saved test data
source=process_step.properties.ProcessingOutputConfig.Outputs["test_data"].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(destination=f"{model_eval_output_uri}", output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/evaluate.py",
property_files=[evaluation_report],
)RegisterModelによるモデルレジストリステップの定義
SageMaker Model Registryを使うと、モデルをカタログ化し、バージョン管理し、選択的に本番環境へデプロイできます。以下のコードをコピーして実行し、モデルレジストリステップを設定します。model_metricsとdrift_check_baselinesという2つのパラメータには、チュートリアルのClarifyCheckStepで計算されたベースライン指標が含まれます。また、独自のベースライン指標も提供可能です。これらのパラメータは、モデルのドリフトチェックやモデルモニタリングで使用されるベースラインを設定するために使用されます。パイプラインが実行されるたびに、新しく計算されたベースラインでこれらのパラメータを更新できます。
# Fetch baseline constraints to record in model registry
model_metrics = ModelMetrics(
bias_post_training=MetricsSource(
s3_uri=model_bias_check_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
explainability=MetricsSource(
s3_uri=model_explainability_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
)
# Fetch baselines to record in model registry for drift check
drift_check_baselines = DriftCheckBaselines(
bias_post_training_constraints=MetricsSource(
s3_uri=model_bias_check_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_constraints=MetricsSource(
s3_uri=model_explainability_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_config_file=FileSource(
s3_uri=model_explainability_config.monitoring_analysis_config_uri,
content_type="application/json",
),
)
# Define register model step
register_step = RegisterModel(
name="XGBRegisterModel",
estimator=xgb_estimator,
# Fetching S3 location where train step saved model artifacts
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[predictor_instance_type],
transform_instances=[predictor_instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status_param,
# Registering baselines metrics that can be used for model monitoring
model_metrics=model_metrics,
drift_check_baselines=drift_check_baselines
)LambdaStepによるモデルのデプロイ
Amazon SageMakerでは、登録されたモデルをさまざまな方法で推論用にデプロイできます。このステップでは、LambdaStep関数を使用してモデルをデプロイします。通常、CI/CDのベストプラクティスに従う堅牢なデプロイにはSageMaker Projectsを使うべきですが、開発・テスト・低トラフィックの内部エンドポイント向けに、軽量なモデルデプロイを行う場合はLambdaStepが便利です。LambdaStepはAWS Lambdaと統合され、サーバー管理を不要にしてパイプライン内でカスタムロジックを実装できます。LambdaStepは、短時間で軽量な操作に適しており、実行時間は最大10分(デフォルトは2分)です。
LambdaStepをパイプラインに追加する方法は2つあります。1つは、既存のLambda関数のARNを使用する方法、もう1つはSageMaker Python SDKのLambdaヘルパークラスを使って新しいLambda関数を作成する方法です。このチュートリアルでは、後者の方法を使用します。以下のコードをコピーして実行し、モデル属性(モデル名など)を受け取ってリアルタイムエンドポイントにデプロイするLambdaハンドラー関数を定義します。
lambda_deployer.pyを生成する。
%%writefile lambda_deployer.py
"""
Lambda function creates an endpoint configuration and deploys a model to real-time endpoint.
Required parameters for deployment are retrieved from the event object
"""
import json
import boto3
def lambda_handler(event, context):
sm_client = boto3.client("sagemaker")
# Details of the model created in the Pipeline CreateModelStep
model_name = event["model_name"]
model_package_arn = event["model_package_arn"]
endpoint_config_name = event["endpoint_config_name"]
endpoint_name = event["endpoint_name"]
role = event["role"]
instance_type = event["instance_type"]
instance_count = event["instance_count"]
primary_container = {"ModelPackageName": model_package_arn}
# Create model
model = sm_client.create_model(
ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=role
)
# Create endpoint configuration
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": instance_count,
"InstanceType": instance_type,
"InitialVariantWeight": 1
}
]
)
# Create endpoint
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)以下のコードにより、LambdaStepを作成します。モデル、エンドポイント名、デプロイ用のインスタンスタイプやインスタンス数などのパラメータは、inputs引数を通じて指定します。
# The function name must contain sagemaker
function_name = "sagemaker-fraud-det-demo-lambda-step"
# Define Lambda helper class can be used to create the Lambda function required in the Lambda step
func = Lambda(
function_name=function_name,
execution_role_arn=sagemaker_role,
script="lambda_deployer.py",
handler="lambda_deployer.lambda_handler",
timeout=600,
memory_size=10240,
)
# The inputs used in the lambda handler are passed through the inputs argument in the
# LambdaStep and retrieved via the `event` object within the `lambda_handler` function
lambda_deploy_step = LambdaStep(
name="LambdaStepRealTimeDeploy",
lambda_func=func,
inputs={
"model_name": pipeline_model_name,
"endpoint_config_name": endpoint_config_name,
"endpoint_name": endpoint_name,
"model_package_arn": register_step.steps[0].properties.ModelPackageArn,
"role": sagemaker_role,
"instance_type": deploy_instance_type_param,
"instance_count": deploy_instance_count_param
}
)ConditionStepによる条件付きステップの定義
このステップでは、ConditionStepを使って、モデルのAUC(Area Under Curve)メトリクスに基づいてモデルの性能を比較します。AUCが0.7以上の場合のみ、パイプラインはバイアスと説明可能性のチェック、モデルの登録、デプロイを行います。こうした条件付きステップは、最適なモデルだけを本番環境にデプロイするのに役立ちます。次のコードをコピーして実行し、条件付きステップを定義します。
# Evaluate model performance on test set
cond_gte = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.roc_auc.value",
),
right=0.7, # Threshold to compare model performance against
)
condition_step = ConditionStep(
name="CheckFraudDetXGBEvaluation",
conditions=[cond_gte],
if_steps=[create_model_step, model_bias_check_step, model_explainability_step, register_step, lambda_deploy_step],
else_steps=[]
)Pipelineの構築と実行
すべてのステップを定義した後、SageMaker Pipelinesオブジェクトにそれらを組み立てます。実行順序を指定する必要はなく、SageMaker Pipelinesがステップ間の依存関係に基づいて自動的に実行順序を推定します。
Pipelineの構築
以下のコードにより、パイプラインを設定します。この定義には、ステップ2で定義したパラメータとステップのリストが含まれます。モデル作成、バイアス・説明可能性チェック、モデル登録、Lambdaデプロイなどのステップは、条件付きステップが真と評価された場合にのみ実行され、指定された入力と出力に基づいて順序通りに実行されます。
# Create the Pipeline with all component steps and parameters
pipeline = Pipeline(
name=pipeline_name,
parameters=[process_instance_type_param,
train_instance_type_param,
train_instance_count_param,
deploy_instance_type_param,
deploy_instance_count_param,
clarify_instance_type_param,
skip_check_model_bias_param,
register_new_baseline_model_bias_param,
supplied_baseline_constraints_model_bias_param,
skip_check_model_explainability_param,
register_new_baseline_model_explainability_param,
supplied_baseline_constraints_model_explainability_param,
model_approval_status_param],
steps=[
process_step,
train_step,
evaluation_step,
condition_step
],
sagemaker_session=sess
)# Create a new or update existing Pipeline
pipeline.upsert(role_arn=sagemaker_role)
# Full Pipeline description
pipeline_definition = json.loads(pipeline.describe()['PipelineDefinition'])
pipeline_definitionPipelineの生成を確認する
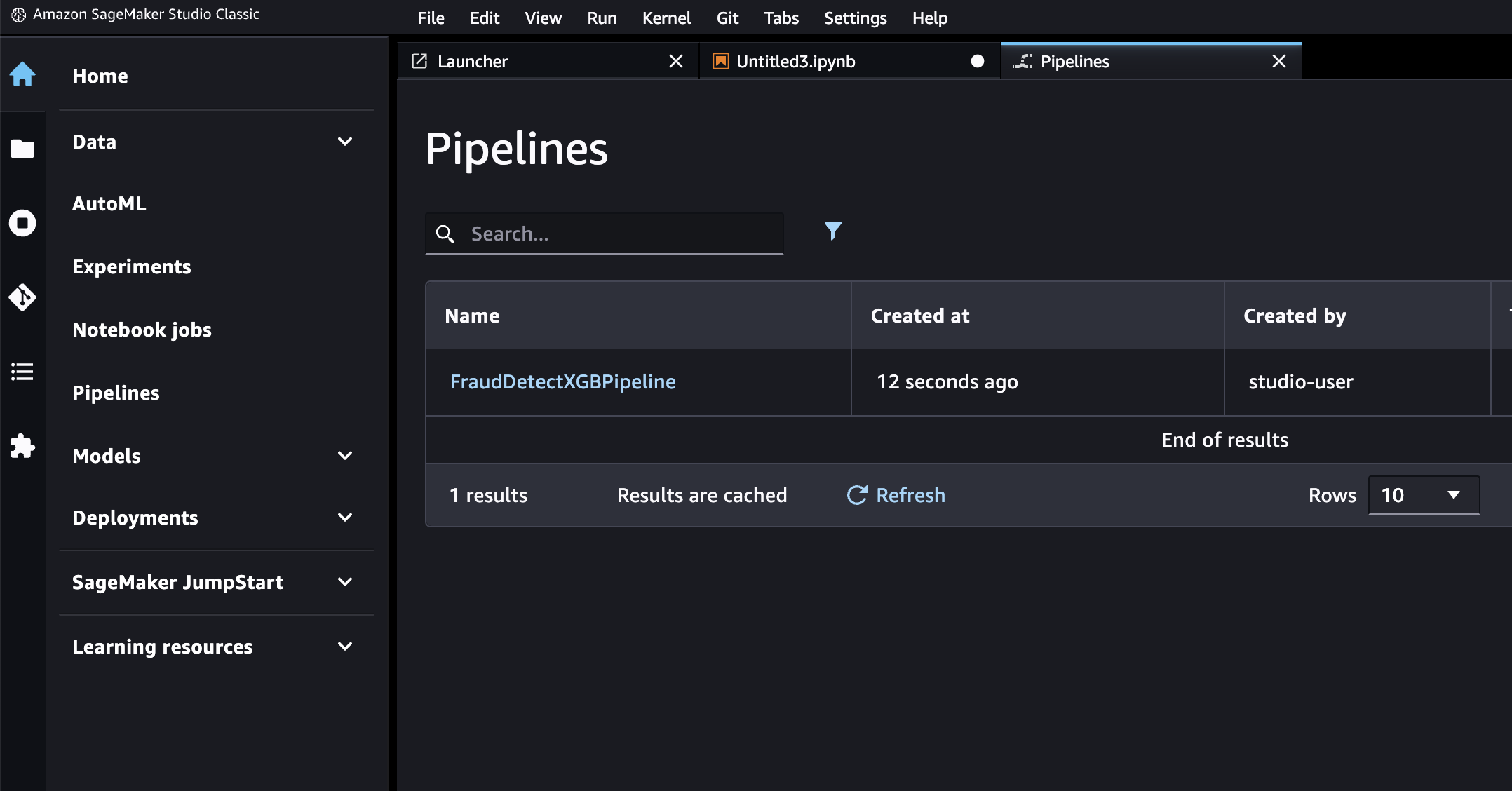
SageMakerはパイプラインを有向非巡回グラフ(DAG)としてエンコードし、各ノードがステップを、ノード間の接続が依存関係を表します。SageMaker StudioでDAGを確認するには、左パネルのSageMaker ResourcesタブでPipelinesを選び、「FraudDetectXGBPipeline」のGraphを選択します。これにより、作成したパイプラインのステップがノードとして表示され、SageMakerがステップ定義に基づいて推論した依存関係が確認できます。
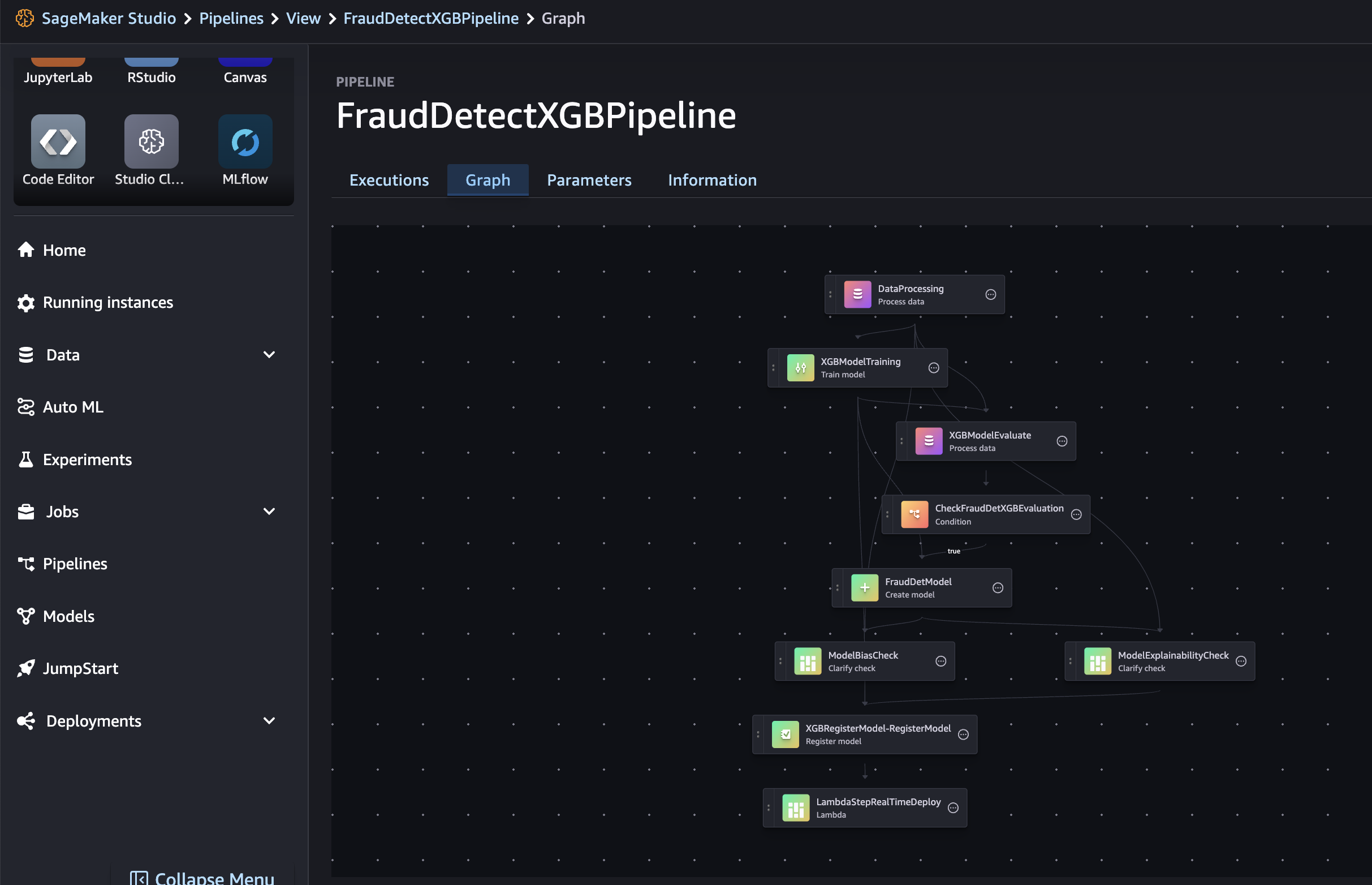
Pipelineの実行
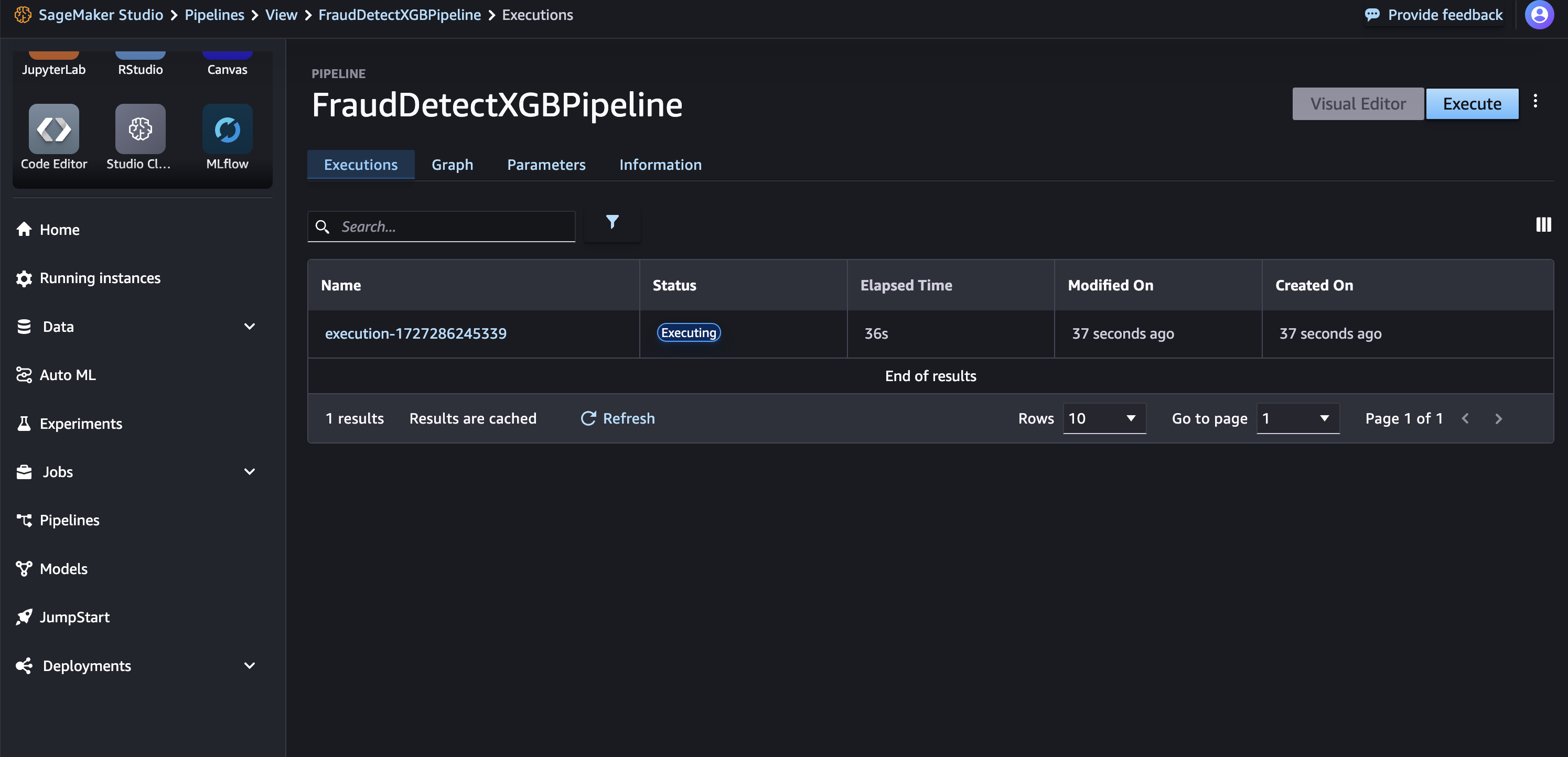
次のコードを実行してパイプラインを開始します。このステップでは、実行パラメータを引数として指定します。SageMaker Studioの左パネルでSageMaker Resourcesタブを選び、Pipelinesのドロップダウンリストから「FraudDetectXGBPipeline」を選択し、Executionsを選ぶと、現在のパイプライン実行が一覧表示されます。
# Execute Pipeline
start_response = pipeline.start(parameters=dict(
SkipModelBiasCheck=True,
RegisterNewModelBiasBaseline=True,
SkipModelExplainabilityCheck=True,
RegisterNewModelExplainabilityBaseline=True)
)Pipelineの実行を確認する
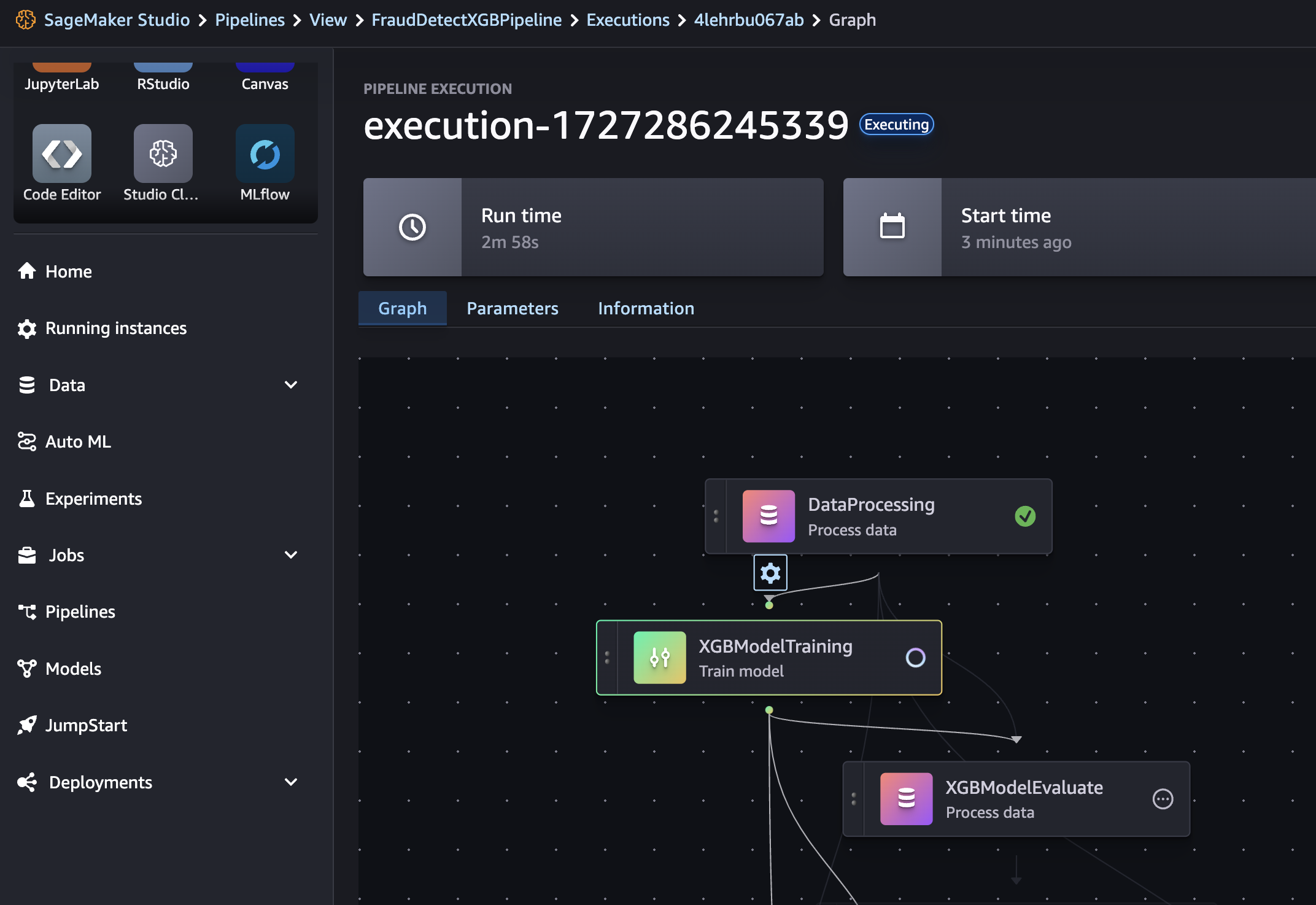
パイプラインの実行状況を確認するには、Statusタブを選択します。すべてのステップが成功すると、グラフ内のノードが緑色になります。
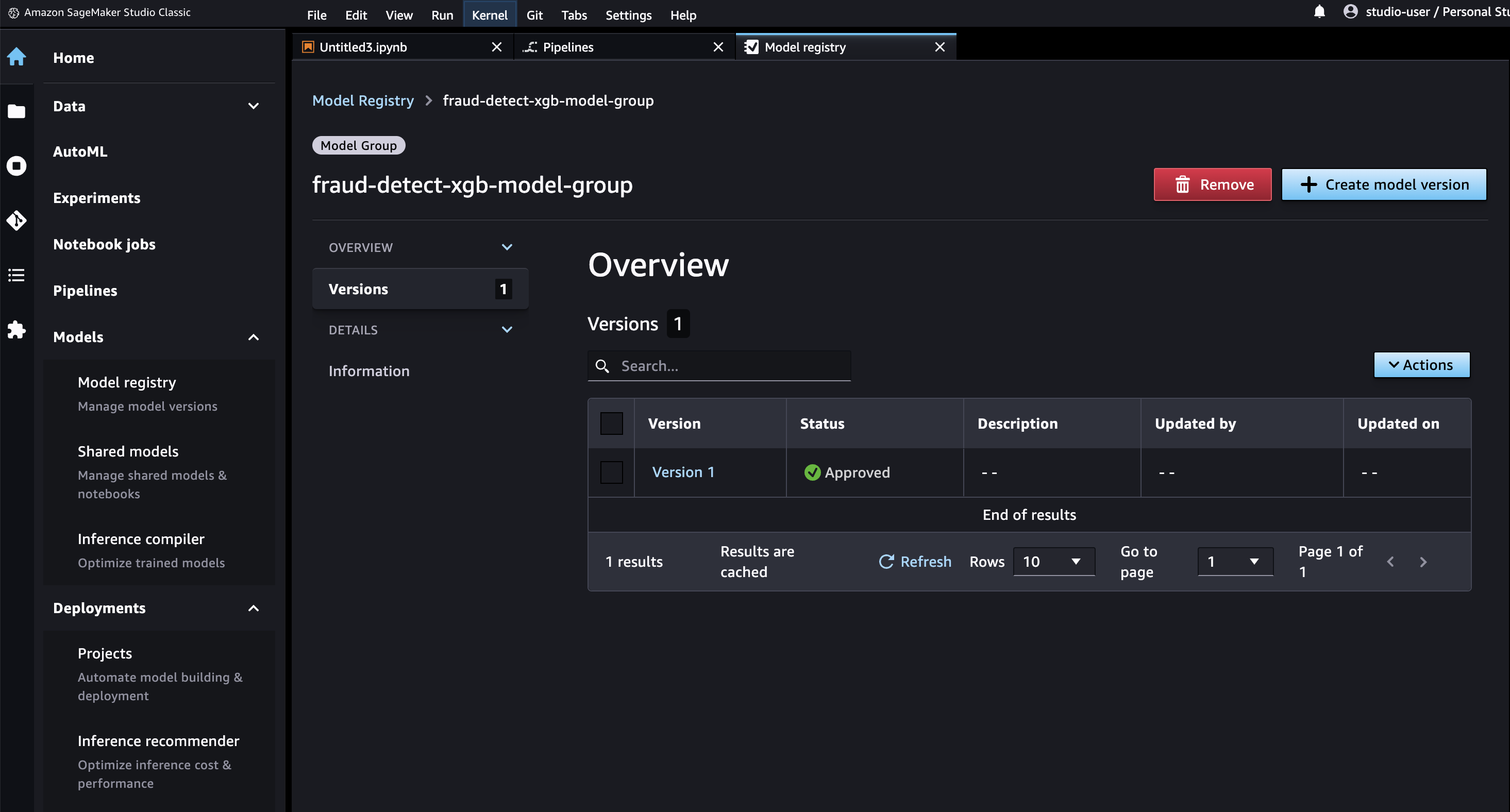
SageMaker StudioにてModel > Model registryを選択すると、左側にモデルグループ名の下に登録されたモデルが表示されます。モデルグループ名を選択すると、モデルのバージョン一覧が表示されます。パイプラインを実行するたびに、評価条件を満たした場合は新しいモデルバージョンがレジストリに追加されます。モデルバージョンを選ぶと、モデルエンドポイントやモデルの説明可能性レポートなどの詳細が表示されます。
Endpoint呼び出しによるPipelineのテスト
このチュートリアルでは、モデルが0.7 AUCのしきい値を超えるスコアを達成したため、条件付きステップがモデルを登録し、リアルタイム推論エンドポイントにデプロイします。SageMaker Studioで、Deployment > Endpointsを選択し、「fraud-detect-xgb-pipeline-endpoint」のステータスがInServiceに変わるのを待ちます。
エンドポイントのステータスがInServiceに変わった後、次のコードをコピーして実行し、サンプル推論を行います。このコードは、テストデータセットの最初の5つのサンプルに対するモデルの予測結果を返します。
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(f"{processing_output_uri}/test_data/test.csv")
# Create SageMaker Predictor from the deployed endpoint
predictor = sagemaker.predictor.Predictor(endpoint_name,
sagemaker_session=sess,
serializer=CSVSerializer(),
deserializer=CSVDeserializer()
)
# Test endpoint with payload of 5 samples
payload = test_df.drop(["fraud"], axis=1).iloc[:5]
result = predictor.predict(payload.values)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_dfPrediction Label
0 [0.1918722540140152] 0
1 [0.06236206740140915] 0
2 [0.04445870965719223] 0
3 [0.08237560093402863] 0
4 [0.06236206740140915] 0
リーソスの削除
# Delete the Lambda function
func.delete()
# Delete the endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)
# Delete the EndpointConfig
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete the model
sm_client.delete_model(ModelName=pipeline_model_name)
# Delete the pipeline
sm_client.delete_pipeline(PipelineName=pipeline_name)